#057. 쿼리개선: 피드 페이지 로직 개선
문제상황
커뮤니티 피드가 느려서 호출하는 로직에 개선이 필요했다.

문제와 해결
(1) 피드에 필요한 레시피, 베이커리 정보 조회 수정
피드는 여러 종류의 글들이 한 번에 보인다. 이 중에서 일반 글(질문글, 잡담글)과 다르게 베이커리 리뷰, 레시피 리뷰는 베이커리과 레시피 데이터를 불러와야한다. 기존에는 피드를 쭉 보면서 매번 데이터를 불러왔다. 그러다보니 매번 베이커리와 레시피를 조회하기 위해 DB와 커넥션을 맺고 통신 하는 과정이 필요했고 특히 DB 섭이 미국에 있다보니 이 과정의 비용이 컸다.
AS_IS
val post: Page<Post> = postRepository.findAll(
pageData.before,
pageRequest,
)
// post를 순회하며 type이 bakeryReview 이거나 recipeReivew이면 해당 데이터를 조회한다
val bakery = bakeryRepository.findByIdOrNull(item.bakeryReview?.bakery?.id ?: 0)
val recipe = recipeRepository.findByIdAndDeletedAtIsNull(item.recipeReview?.recipe?.id ?: 0)
이 부분을 post 중 bakeryId를 들고 있는 경우만 뽑아서 베이커리를 한 번에 조회했다. 레시피도 마찬가지로 수정했다. 이렇게 수정하면 데이터가 필요할 때마다 매번 DB와 커넥션을 맺고 조회해오는 과정이 한 번 이하로 줄어들면서 데이터를 조회해오는 속도가 빨라진다. 피드가 매번 10개씩만 불러오는 정도여서 배열로 만들어서 쓰긴했지만 이 O(1)로 만들고 싶다면 map 자료 구조로 만드는 방법도 있다.
node 환경이었다면 Promise.all 을 통해서 비동기적으로 거의 동시에 요청을 보내 추가적으로 속도 개선을 해볼 수 있었을 것 같다. 코틀린에서는 코루틴을 사용할 수 있을 것 같은데, 이 부분은 이번 글에서는 다루지 않는다.
TO_BE
val post: Page<Post> = postRepository.findAll(
pageData.before,
pageRequest,
)
// post 중 bakeryId를 들고 있는 경우만 뽑아서 베이커리를 한 번에 조회한다
val bakeryIds = result.content.mapNotNull { item -> item.bakeryReview?.bakery?.id }
val bakeries = bakeryRepository.findAllById(bakeryIds)
// 마찬가지로 post 중 recipeId를 들고 있는 경우만 뽑아서 레시피를 한 번에 조회한다
val recipeIds = result.content.mapNotNull { item -> item.recipeReview?.recipe?.id }
val recipes = recipeRepository.findAllByIdInAndDeletedAtIsNull(recipeIds)
이 과정에서 재미있었던 부분은 bakeryIds를 뽑으면 null이 포함된 배열이 나오는데 null을 어떻게 필터링 할까에 대한 매서드가 만들어져있다는 것이다. JS같은 경우 이렇게 defined 된 값만 뽑아내기 위해 typeguard를 만들어야 하는데 kotlin은 Collection의 내장 매서드로 지원한다.
function isDefined<T>(x: T | undefined): x is T {
return x !== undefined;
}
// 테스트
describe('isDefined', () => {
it('undefined 는 리턴되지 않는다', () => {
// given
const arr = [undefined, 'a', 'b'];
const expected = ['a', 'b'];
// when
const result = arr.filter(isDefined);
// then
expect(result).toStrictEqual(expected);
});
});확실히 kotlin을 쓰면 이러한 null, undefined 값을 해결하기 위한 노력을 했다는 것을 곳곳에서 볼 수 있는 것 같다. 굉장히 편한데 단점은 다른 언어를 쓰려고 할 때는 쓸 수 없다는 것..
/**
* Returns a list containing only the non-null results of applying the given [transform] function
* to each element in the original collection.
*
* @sample samples.collections.Collections.Transformations.mapNotNull
*/
public inline fun <T, R : Any> Iterable<T>.mapNotNull(transform: (T) -> R?): List<R> {
return mapNotNullTo(ArrayList<R>(), transform)
}
(2) 댓글 갯수를 불러오는 로직 수정
피드에는 댓글 갯수를 보여주는 로직도 포함되어 있다. 기존에는 피드 하나마다 실제 댓글 테이블을 접근해서 갯수를 count로 세왔다. 댓글 갯수는 피드의 메타정보이다. 이후에는 좋아요수, 조회수 등 다양한 메타 정보가 추가될 예정이다. 이전과 같은 방식이라면 피드 하나당 메타정보를 조회하는 추가 쿼리들이 붙어야한다. 따라서 이 정보는 피드 테이블에 컬럼을 추가해서 해결했다. 피드 테이블에 컬럼이 많다면 메타 정보 테이블을 분리하는 방법도 있지만, (1) 피드 테이블은 테이블의 공통 정보를 가지고 있는 테이블이다 라는 점과 (2) 불필요한 join을 줄인다는 점에서 피드 테이블에 컬럼을 추가해도 괜찮다고 생각했다.
AS_IS
val postIds = result.content.map { item -> item.id }
val commentCounts = commentService.countCommentsByPostIds(postIds) // <--- postId에 해당하는 comment 정보를 직접 조회
TO_BE
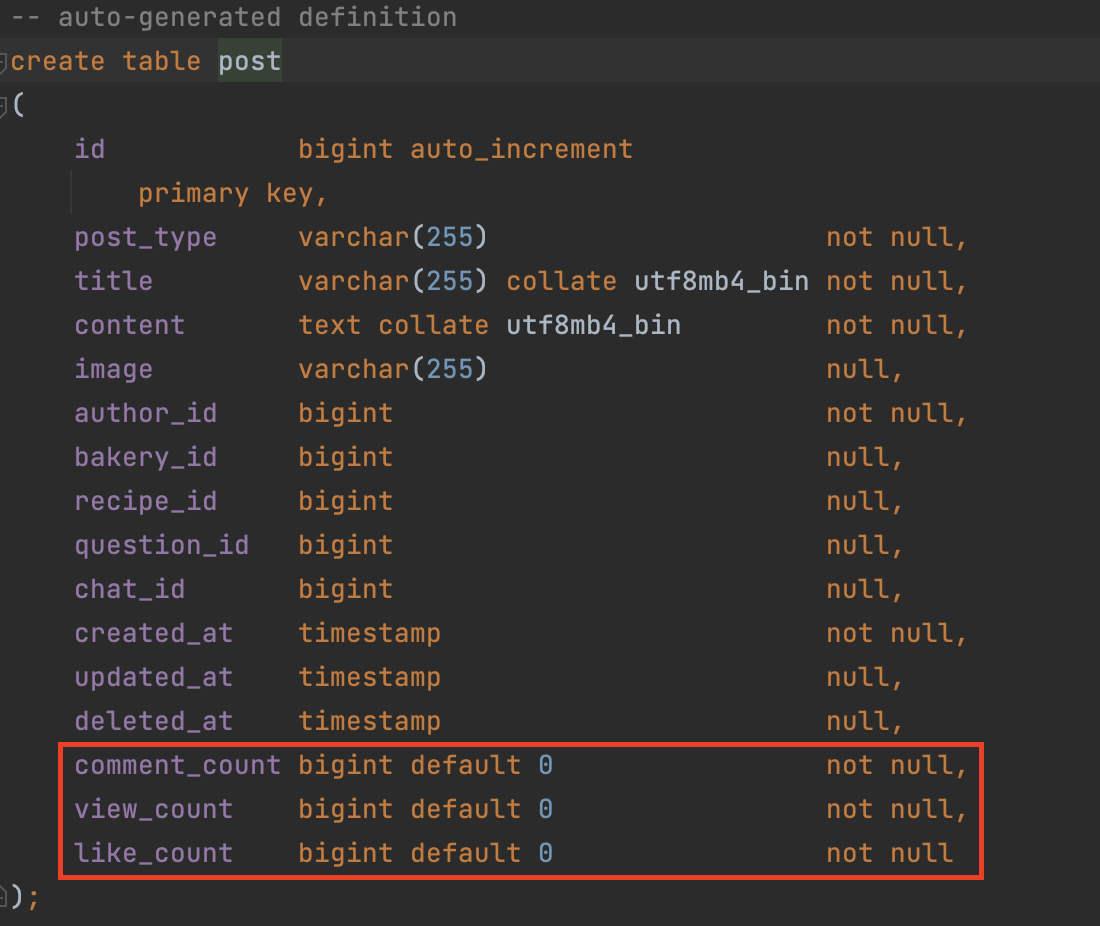
테이블을 생성할 때 nullable 하지 않은 컬럼으로 만들었다. 0을 기본 값으로 가지고 있도록 설정했다.
그리고 기존의 comment 정보를 마이그레이션 했다.
UPDATE post AS p
SET p.comment_count = coalesce((SELECT count(1) from comment
where deleted_at is null
and p.id = comment.post_id
group by post_id), 0);
그리고 comment 가 추가되거나 삭제되면 해당 정보를 피드 테이블 메타 정보에 업데이트하도록 설정했다.
결과
결과적으로 시간을 1/3 정도로 단축. 다만 로컬에서 서버를 띄우면 위치적으로 미국 Redis, DB 에 한국 서버가 되어 총 시간이 4초 정도 소요 됨. (DB를 한 번 호출할 때마다 최소 300ms 이상 소요) -> 하지만 실제 사용 환경에서는 서버까지 미국에 떠있기 때문에 이정도로 오래 걸리지 않는다.

실제 서버 호출 화면:
커뮤니티 탭에 들어간 후 커뮤니티라는 화면이 상단에 뜨기까지는 웹뷰 로딩 시간.
웹뷰가 로딩된 이후로 피드를 불러오기까지는 사용자가 사용하기에 크게 부담 될 정도의 시간은 아닌 것 같다