개념
Inner Join이 3개 적용되어 총 4개의 테이블을 연결하던 쿼리의 속도 개선.
아래는 작업한 코드를 약간 변형시킨 코드로, 작가 한 명이 벌어들인 수익의 총 합을 구하는 계산식이다.
각 테이블의 크기는 다음과 같다.
books: 7196
carts: 11,387,585
price: 854,891
author: 8044
SELECT a.user_id id, SUM(p.amount) total
FROM books b
INNER JOIN carts ct ON b.id = ct.book_id AND ct.status = '결제완료'
INNER JOIN price p ON p.cart_id = ct.id
INNER JOIN author a ON b.id = a.book_id AND a.type = 'main'
WHERE b.deleted_at IS NULL
AND b.status IN ('publish')
AND a.user_id = 74366
AND ct.deleted_at IS NULL
GROUP BY author_id;이 쿼리의 실행계획을 살펴보면 다음과 같다
- execution time: 캐싱이 되어있지 않을 때에는 약 30s, 캐싱이 되면 1s 내외이다.
- carts 테이블이 1천만개로 index 스캔을 하더라도 slow query가 걸리고 있다.
- 드라이빙, 드리븐 테이블의 순서에 관계없이 테이블을 읽는 순서를 조정하고 있다. (postgresql, innoDB 엔진)

개선
이 join으로 네 개의 테이블이 연결되면서 데이터 양이 많아져 느려진 쿼리이므로 IN절을 이용해 N+M으로 분리했다.
(1) carts 테이블
carts 테이블이 무거운데 실행계획을 살펴보면 아래와 같다. 위 쿼리를 확인해보면 cart 는
1) book_id 와 연간관계가 있다
2) status가 결제완료이다
3) deleted_at is NULL
이 세 가지 조건으로 구성되어 있다. 지금 사용하고 있는 인덱스는 book_id 와 status 만 가지고 있기 때문에 커버링 인덱스를 사용하지는 못한다. 그래서 Index Scan Node에 index를 읽는 작업과 실제 테이블을 읽는 작업 두 가지가 실행되었다고 알려주고 있다. 실제 Misc를 살펴보면 deleted_at 으로 Filter 작업을 한 것을 알 수 있다. 하지만 cart의 특성상 삭제된 레코드는 없는 지 filter한 row는 없었다.
* 커버링 인덱스를 사용하면 속도가 조금 더 빨라질 지는 테스트가 필요한 부분이지만 여기에서는 한 쿼리에서 보는 데이터 양을 줄이는 것에 집중하려고 한다.
(2) 접근하는 데이터 수 줄이기
book * carts * author * price 네 가지 테이블을 모두 접근하면서 최악의 경우 모든 테이블의 rows를 곱한 데이터에 접근하는 상황이 된다. 이를 피하기 위해 쿼리를 둘로 쪼개 봐야하는 데이터를 줄일 수 있다.
위의 쿼리를 살펴보면 결국 구하고자 하는 것은
- 특정 author (author는 valid해야한다)의 valid한 book들
- 이 book이 담긴 cart의 가격정보 price.amount의 합을 구한다
이렇게 쪼갤 수 있다.
이를 쿼리로 작성하면 아래와 같다.
SELECT b.id
FROM book b
INNER JOIN author a ON b.id = a.book_id
WHERe a.user_id = 74366
AND a.type = 'main'
AND b.status IN ('publish')
AND b.deleted_at IS NULLselect p.id
from price p
inner join carts ct on ct.id = p.cart_id
where ct.book_id IN (
327260,
326674,
326277,
...
330459
)
AND b.status = '결제완료'
AND b.deleted_at IS NULL
실행계획에서 살펴보면
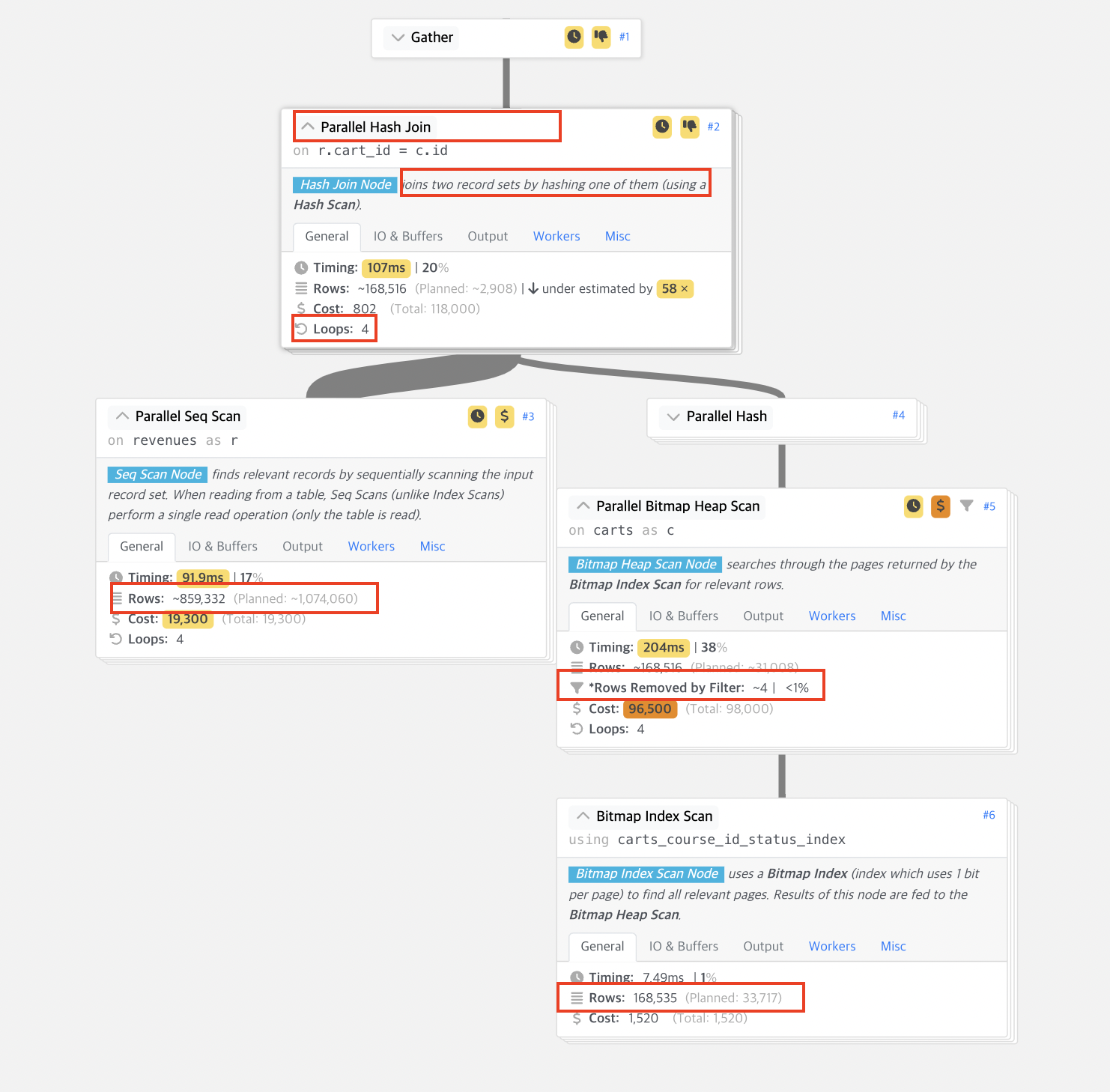
기존 쿼리는 carts에서 16만 8천 개를 가지고 와서 author*book 정보와도 Nested Loop (모든 레코드를 직접 loop하면서 찾는 것) 하고 있고 (slow + cost) 이 결과를 price 테이블과 합치면서도 다시 Nested Loop을 사용하고 있다. 즉 위에서 생각한 최악의 케이스에 가깝다.
반면 개선한 결과를 살펴보면 author*book의 결과가 분리되어 있고,
carts*price 실행계획을 살펴보면 여기에서도 마찬가지로 16만 8천개의 carts 데이터를 대상으로 하지만, price 테이블과 합할 때 Parallel Hash Join 즉, 해시로 조인하면서 단 4번만 Loop을 돈다는 것을 알 수 있다.
그 결과 기존 캐시 처리 되었을 때 1s+ 걸리던 작업을 504ms 로 줄일 수 있다.
'백엔드 개발' 카테고리의 다른 글
| #033. 리팩터링: Transaction DB 와 Query DB 분리하기 (Mikro ORM) (0) | 2023.04.21 |
|---|---|
| #032. GCP 서비스로 개발 환경 배포하기(spring profile + cloudrun + cloudflare) (0) | 2023.04.12 |
| #030. CORS 에러 원인과 해결 (feat. 서버에서 CORS 테스트 하기) (0) | 2023.04.08 |
| #029. 리팩터링: any 보다 unknown 타입 사용하기 (feat. 이중 단언문) (0) | 2023.04.05 |
| #028. TS 타입 좁히기(2) Brand 사용해 nominal typing 하기 (0) | 2023.03.22 |



