개념
Transaction DB 와 Query DB 분리해야하는 이유
트랜젝션은 하나의 논리적인 작업셋으로 COMMIT이 되면 실행을 ROLLBACK이 되면 아무것도 적용되지 않는다. 트랜젝션이 시작되면 DB와 커넥션을 맺게 되므로 트랜젝션이 길어질수록 DB의 여유 스레드는 줄어든다. 어느 순간에는 커넥션을 위해 기다려야 한다. 트랜젝션은 가장 작은 단위로 가져가야 한다. 그리고 이와 같은 커넥션 제한 등의 이유로 조회 DB와 마스터 DB를 분리하는 것이 좋다. 따라서 만약 application에서 다음과 같이 transaction 안에서 조회용 쿼리 코드가 있다면 이를 트랜젝션 바깥으로 빼도록 수정하는 것이 좋다.
private async update(
id: number,
dto: UpdateRequest,
): Promise<number> {
await this.transactionService.transactional(async (manager) => { // --------------------> trancation 시작
const news = await this.queryRepository.findOne(id, dto.userId); // <----- "조회용 쿼리"
if (!entity) { // --------------------> validation
throw new NotFoundException('기존 글이 존재하지 않습니다');
}
entity.update( // --------------------> entity 업데이트
dto.a,
dto.b,
dto.c,
dto.d,
dto.e,
);
manager.persist(entity);
}); // --------------------> transaction 종료
}
아래와 같이 트랜젝션 바깥으로 뺄 수 있다.
private async update(
id: number,
dto: UpdateRequest,
): Promise<number> {
const news = await this.queryRepository.findOne(id, dto.userId); // <----- "조회용 쿼리"
if (!entity) { // --------------------> validation
throw new NotFoundException('기존 글이 존재하지 않습니다');
}
entity.update( // --------------------> entity 업데이트
dto.a,
dto.b,
dto.c,
dto.d,
dto.e,
);
await this.transactionService.transactional(async (manager) => { // --------------------> trancation 시작
manager.persist(entity);
}); // --------------------> transaction 종료
}
DB를 분리했을 때 slave replication 복제 지연시간 이슈:
이렇게 트랜젝션을 처리하는 master DB와 조회 쿼리를 처리하는 replication DB가 분리 되면 이 둘 간의 복제 지연 시간이 문제 될 수 있다. 예를 들어 어떤 데이터를 넣자마자 조회해오는 경우 데이터 처리는 master DB에서 이뤄지고 조회는 replication DB에서 이뤄지기 때문에 insert 된 데이터가 아직 복제본 DB에 업데이트 되지 않아 id로 찾지 못하는 경우가 있다.
마스터 DB에서 조회 DB로 데이터 복제는 이론적으로 생성 즉시 이뤄진다. 하지만 네트워크 시간 등으로 인해 지연이 생기는데 이를 "레플리케이션 랙(replication lag)"이라고 한다. 때에 따라 다르지만 아래와 같이 실제 서버의 레플리케이션 랙 모니터링 도구를 살펴보면 10ms 라는 아주 작은 시간 내외에서 이뤄지는 것을 확인할 수 있다.
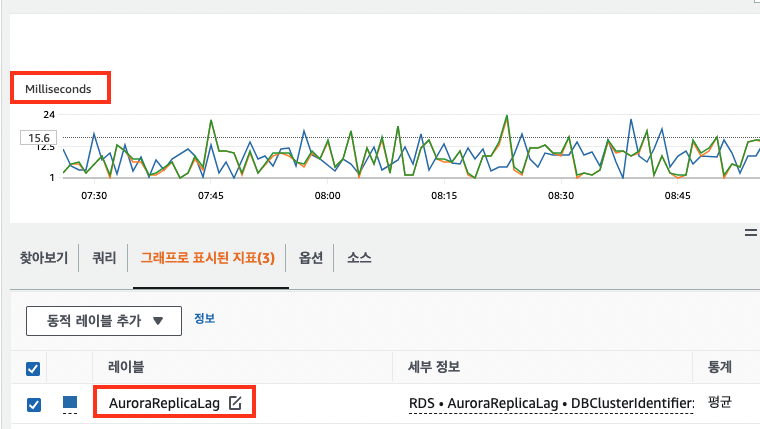
또한 ORM을 사용하는 서버 개발의 관점에서도 영속성 컨텍스트를 생각해볼 수 있다. 영속성 컨텍스트에서 해당 도메인 객체를 관리하므로, 생성 후 조회하면 DB를 조회하는 것이 아니라 영속성 컨텍스트에서 관리하는 객체를 조회한다. 따라서 위의 이슈가 문제되지 않는다.
Mikro ORM에 적용
Mikro ORM에서는 mikro-orm 설정 파일에 replicas라고 해서 master DB와는 다른 조회용 DB를 설정할 수 있다.
// mikro-orm.config.ts
const config: MikroOrmModuleOptions = {
type: 'postgresql',
host: env.masterHost, // master DB
user: env.userName,
password: env.password,
dbName: env.name,
replicas: [{ host: env.readerHost }], // read-only DB
...
};
리더용 DB는 array 값을 넣어 여러개를 설정할 수 있다
- 기본적인 설정
구체적인 설정이 없다면 조회 쿼리 시에 랜덤으로 replicas 중 하나를 선택해서 조회 쿼리를 수행한다.
- 명시적인 설정
const connection = em.getConnection(); // ----------> write connection
const readConnection = em.getConnection('read'); // ----------> random read connection
const qb1 = em.createQueryBuilder(Author);
const res1 = await qb1.select('*').execute(); // ----------> 기본설정: random read connection
const qb2 = em.createQueryBuilder(Author, 'a', 'write');
const res2 = await qb2.select('*').execute(); // ----------> 'write'라는 쿼리 타입을 지정하면 master를 본다: write connection
// all queries inside a transaction will use write connection
await em.transactional(async em => {
const a = await em.findOne(Author, 1); // write connection
const b = await em.findOne(Author, 1, { connectionType: 'read' }); // ----------> transaction 안이라도 type을 지정하면 reader DB를 본다
a.name = 'test'; // will trigger update on write connection once flushed
});
그리고 실제 쿼리에서 이렇게 확인해볼 수 있다.
실제 내 쿼리가 어떤 DB를 보고 있는 지는 debug 모드로 확인해볼 수 있다.
우선 mikro-orm config 파일의 debug:true로 디버그 모드를 설정한 후 transaction 쿼리와 조회용 쿼리를 하나씩 테스트 해본다.
[transaction 쿼리]: update 문을 사용하면 'via write connection' 이라고 안내가 되고

[조회용 쿼리]: select 문을 사용하면 'via read connection' 이라고 안내된다.

'백엔드 개발' 카테고리의 다른 글
| #035. 쿼리개선 : InnerJoin / OuterJoin 과 인덱스 (0) | 2023.05.01 |
|---|---|
| #034. 쿼리개선: "연산"을 해서 index를 사용하지 못한 쿼리 개선 (0) | 2023.04.25 |
| #032. GCP 서비스로 개발 환경 배포하기(spring profile + cloudrun + cloudflare) (0) | 2023.04.12 |
| #031. 쿼리개선: N*M -> N+M 개선하기 (0) | 2023.04.09 |
| #030. CORS 에러 원인과 해결 (feat. 서버에서 CORS 테스트 하기) (0) | 2023.04.08 |



